在和原生DOM选择中,这在之前的学习尤大的知乎回答的时候就已经有过回答,这是一个性能 VS 可维护性的取舍。 首先没有任何框架可以比纯手动的优化 DOM 操作更快,因为框架的 DOM 操作层需要应对任何上层 API 可能产生的操作,它的实现必须是普适的。首先,看下面的例子
1 2 3 4 5 6 7 8 9
let div = document.createElement('div') let str = '' for (const key in div) { str += key + '' } console.log(str) //aligntitlelangtranslatedirhiddenaccessKeydraggablespellcheckautocapitalizecontentEditableisContentEditableinputModeoffsetParentoffsetTopoffsetLeftoffsetWidthoffsetHeightstyleinnerTextouterTextonbeforexrselectonabortonbluroncanceloncanplayoncanplaythroughonchangeonclickoncloseoncontextmenuoncuechangeondblclickondragondragendondragenterondragleaveondragoverondragstartondropondurationchangeonemptiedonendedonerroronfocusonformdataoninputoninvalidonkeydownonkeypressonkeyuponloadonloadeddataonloadedmetadataonloadstartonmousedownonmouseenteronmouseleaveonmousemoveonmouseoutonmouseoveronmouseuponmousewheelonpauseonplayonplayingonprogressonratechangeonresetonresizeonscrollonsecuritypolicyviolationonseekedonseekingonselectonslotchangeonstalledonsubmitonsuspendontimeupdateontoggleonvolumechangeonwaitingonwebkitanimationendonwebkitanimationiterationonwebkitanimationstartonwebkittransitionendonwheelonauxclickongotpointercaptureonlostpointercaptureonpointerdownonpointermoveonpointeruponpointercancelonpointeroveronpointeroutonpointerenteronpointerleaveonselectstartonselectionchangeonanimationendonanimationiterationonanimationstartontransitionrunontransitionstartontransitionendontransitioncanceloncopyoncutonpastedatasetnonceautofocustabIndexattachInternalsblurclickfocusenterKeyHintvirtualKeyboardPolicyonpointerrawupdatenamespaceURIprefixlocalNametagNameidclassNameclassListslotattributesshadowRootpartassignedSlotinnerHTMLouterHTMLscrollTopscrollLeftscrollWidthscrollHeightclientTopclientLeftclientWidthclientHeightattributeStyleMaponbeforecopyonbeforecutonbeforepasteonsearchelementTimingonfullscreenchangeonfullscreenerroronwebkitfullscreenchangeonwebkitfullscreenerrorchildrenfirstElementChildlastElementChildchildElementCountpreviousElementSiblingnextElementSiblingafteranimateappendattachShadowbeforeclosestcomputedStyleMapgetAttributegetAttributeNSgetAttributeNamesgetAttributeNodegetAttributeNodeNSgetBoundingClientRectgetClientRectsgetElementsByClassNamegetElementsByTagNamegetElementsByTagNameNSgetInnerHTMLhasAttributehasAttributeNShasAttributeshasPointerCaptureinsertAdjacentElementinsertAdjacentHTMLinsertAdjacentTextmatchesprependquerySelectorquerySelectorAllreleasePointerCaptureremoveremoveAttributeremoveAttributeNSremoveAttributeNodereplaceChildrenreplaceWithrequestFullscreenrequestPointerLockscrollscrollByscrollIntoViewscrollIntoViewIfNeededscrollTosetAttributesetAttributeNSsetAttributeNodesetAttributeNodeNSsetPointerCapturetoggleAttributewebkitMatchesSelectorwebkitRequestFullScreenwebkitRequestFullscreenariaAtomicariaAutoCompleteariaBusyariaCheckedariaColCountariaColIndexariaColSpanariaCurrentariaDescriptionariaDisabledariaExpandedariaHasPopupariaHiddenariaKeyShortcutsariaLabelariaLevelariaLiveariaModalariaMultiLineariaMultiSelectableariaOrientationariaPlaceholderariaPosInSetariaPressedariaReadOnlyariaRelevantariaRequiredariaRoleDescriptionariaRowCountariaRowIndexariaRowSpanariaSelectedariaSetSizeariaSortariaValueMaxariaValueMinariaValueNowariaValueTextgetAnimationsnodeTypenodeNamebaseURIisConnectedownerDocumentparentNodeparentElementchildNodesfirstChildlastChildpreviousSiblingnextSiblingnodeValuetextContentELEMENT_NODEATTRIBUTE_NODETEXT_NODECDATA_SECTION_NODEENTITY_REFERENCE_NODEENTITY_NODEPROCESSING_INSTRUCTION_NODECOMMENT_NODEDOCUMENT_NODEDOCUMENT_TYPE_NODEDOCUMENT_FRAGMENT_NODENOTATION_NODEDOCUMENT_POSITION_DISCONNECTEDDOCUMENT_POSITION_PRECEDINGDOCUMENT_POSITION_FOLLOWINGDOCUMENT_POSITION_CONTAINSDOCUMENT_POSITION_CONTAINED_BYDOCUMENT_POSITION_IMPLEMENTATION_SPECIFICappendChildcloneNodecompareDocumentPositioncontainsgetRootNodehasChildNodesinsertBeforeisDefaultNamespaceisEqualNodeisSameNodelookupNamespaceURIlookupPrefixnormalizeremoveChildreplaceChildaddEventListenerdispatchEventremoveEventListener
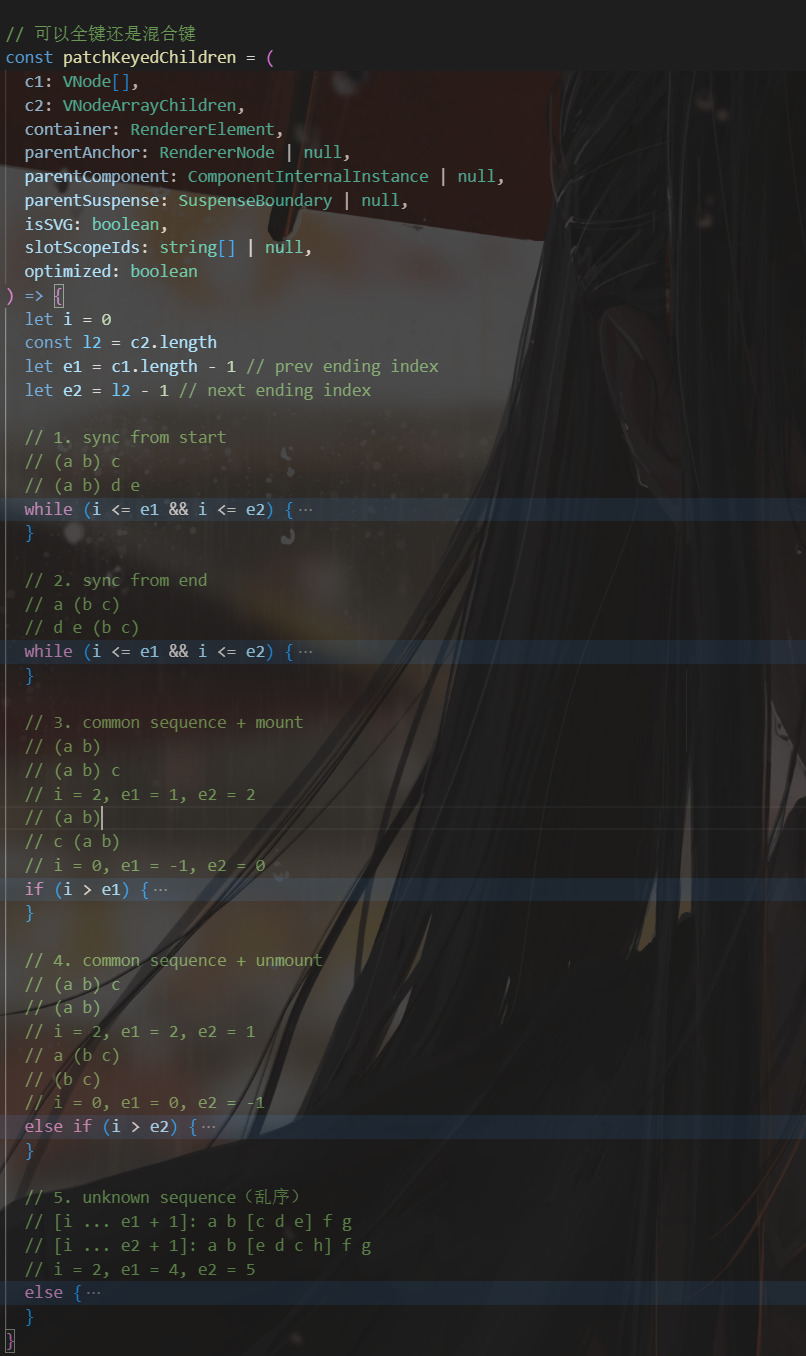
//注意,这是经过之前两步计算的 // oldChildrenEnd 旧的子节点最大(最后一个)下标 // newChildrenEnd 新的子节点最大(最后一个)下标 // (a b) // (a b) c // i = 2, oldChildrenEnd = 1, newChildrenEnd = 2 // (a b) // c (a b) // i = 0, oldChildrenEnd = -1, newChildrenEnd = 0
// 3. 新节点多余旧节点时的 diff 比对。 // i > oldChildrenEnd 就是旧的比较渲染完了 if (i > oldChildrenEnd) { // i <= newChildrenEnd 就是新的还有 if (i <= newChildrenEnd) { const nextPos = newChildrenEnd + 1//剩余新节点的长度 // 重点:找到锚点 const anchor = nextPos < newChildrenLength ? newChildren[nextPos].el : parentAnchor while (i <= newChildrenEnd) { patch(null, normalizeVNode(newChildren[i]), container, anchor) i++ } } }
// 5. unknown sequence // [i ... e1 + 1]: a b [c d e] f g // [i ... e2 + 1]: a b [e d c h] f g // i = 2, e1 = 4, e2 = 5 else { // 旧子节点的开始索引:oldChildrenStart const s1 = i // 新子节点的开始索引:newChildrenStart const s2 = i